CNN
CNN
如果用全连接神经网络处理大尺寸图像具有三个明显的缺点:
(1)首先将图像展开为向量会丢失空间信息; (2)其次参数过多效率低下,训练困难; (3)同时大量的参数也很快会导致网络过拟合。
而使用卷积神经网络可以很好地解决上面的三个问题。
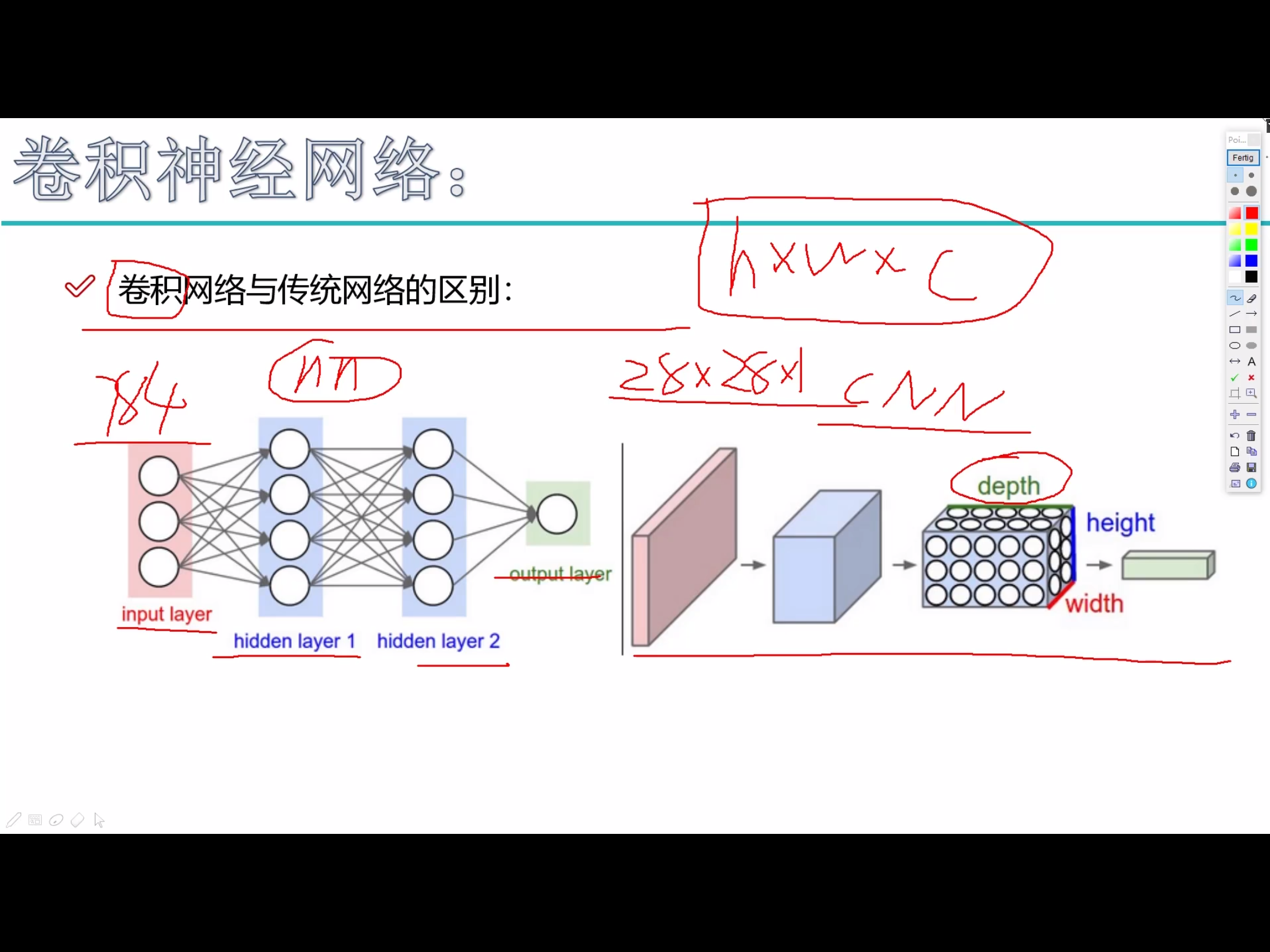
与常规神经网络不同,卷积神经网络的各层中的神经元是 3 维排列的:宽度、高度和深度。其中的宽度和高度是很好理解的,因为本身卷积就是一个二维模板,但是在卷积神经网络中的深度指的是 激活数据体 的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数。
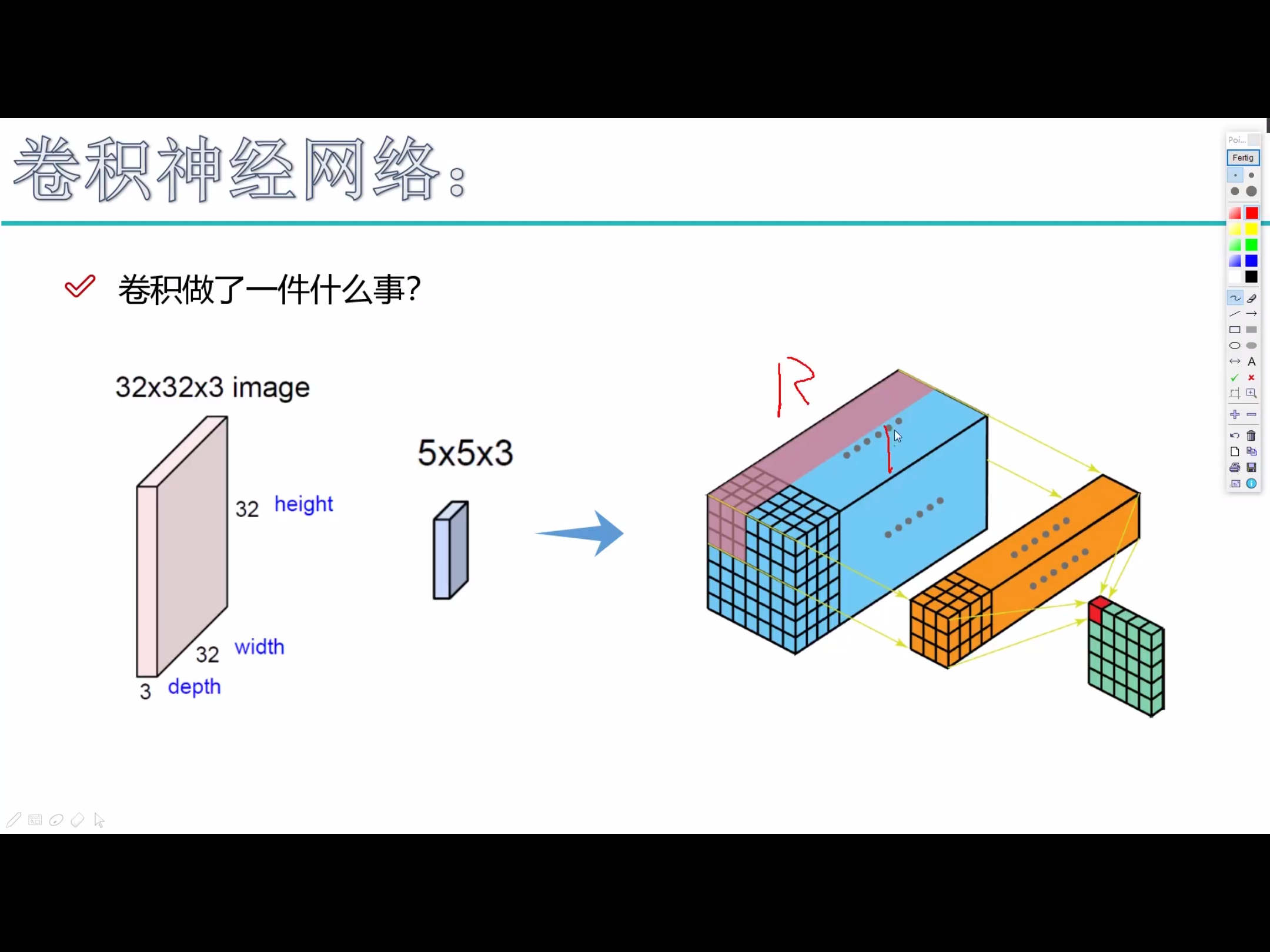
举个例子来理解什么是宽度,高度和深度,假如使用CIFAR-10中的图像是作为卷积神经网络的输入,该 输入数据体 的维度是32x32x3(宽度,高度和深度)。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。 对于用来分类CIFAR-10中的图像的卷积网络,其最后的输出层的维度是1x1x10,因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。
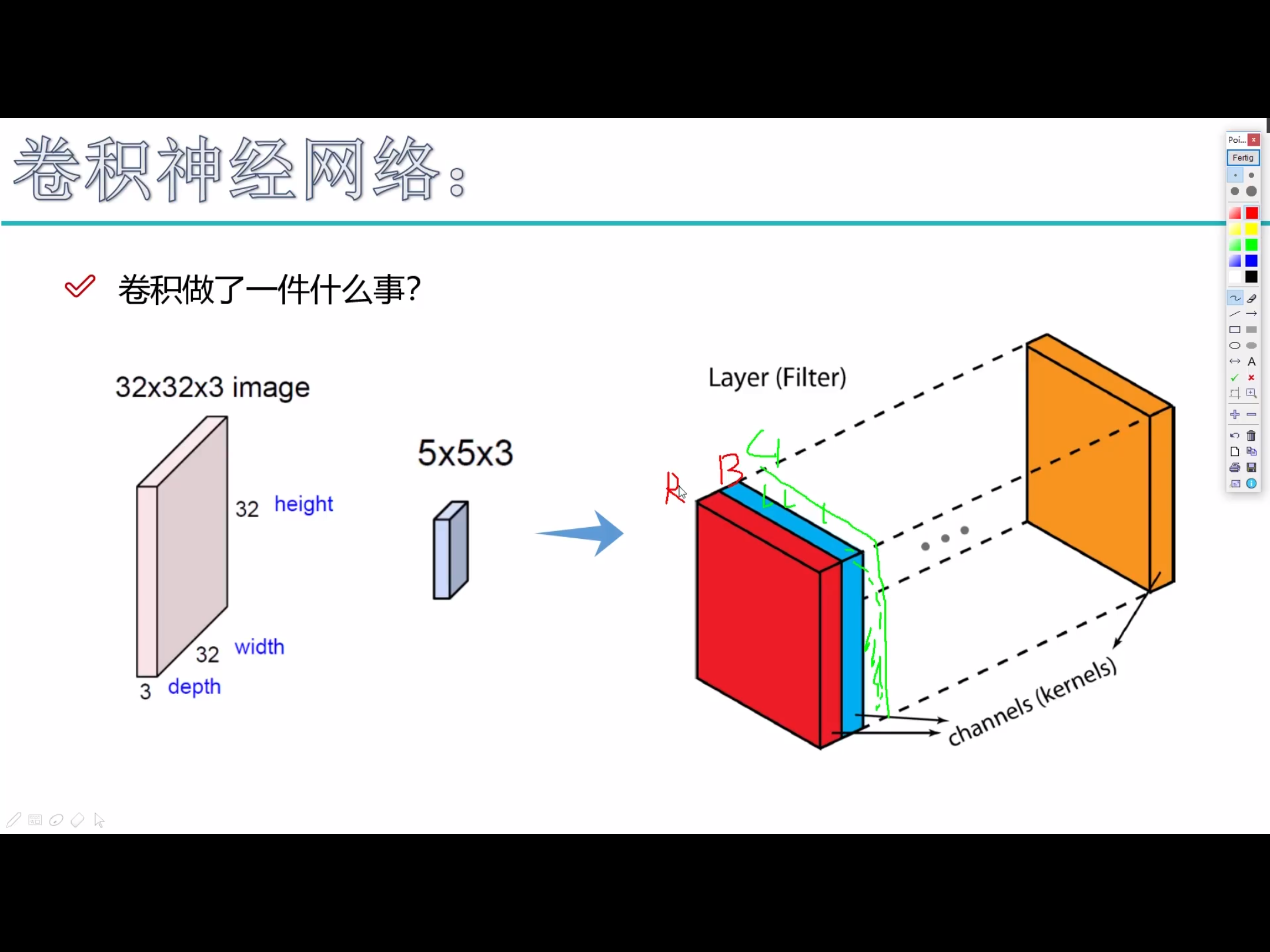
卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width, height, depth (height * width * channel ) (注意这个 depth 不是神经网络的深度,而是用来描述神经元的) 。比如输入的图片大小是 32 × 32 × 3 (rgb),那么输入神经元就也具有 32×32×3 的维度。下面是图解
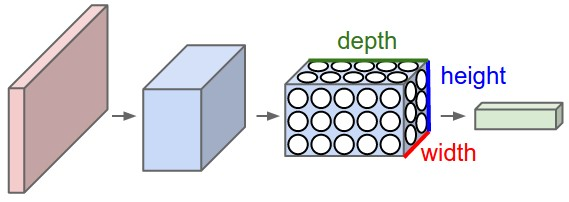
我的理解是卷积核就相当于神经元,但这个神经元是局部连接的,就是说一个神经元/卷积核只接受卷积核尺寸大小的数据输入,对输入的数据通过卷积核内的权重和偏置进行一次卷积运算,得到一个输出值,通过多次移动便得到了一层激活层的输出。权值共享的意思也就是这个神经元/卷积核在移动中用的是同一组权重和偏置
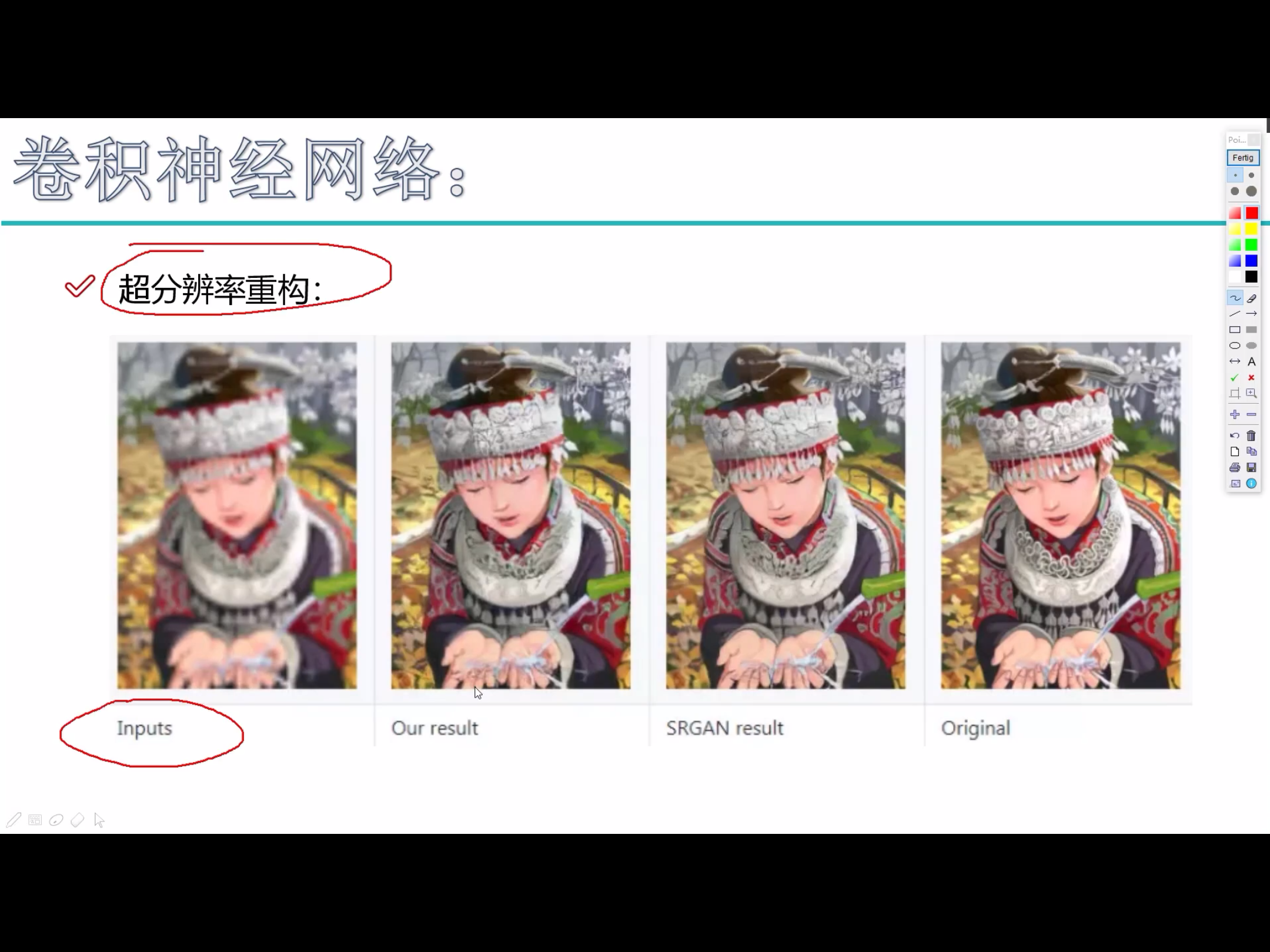
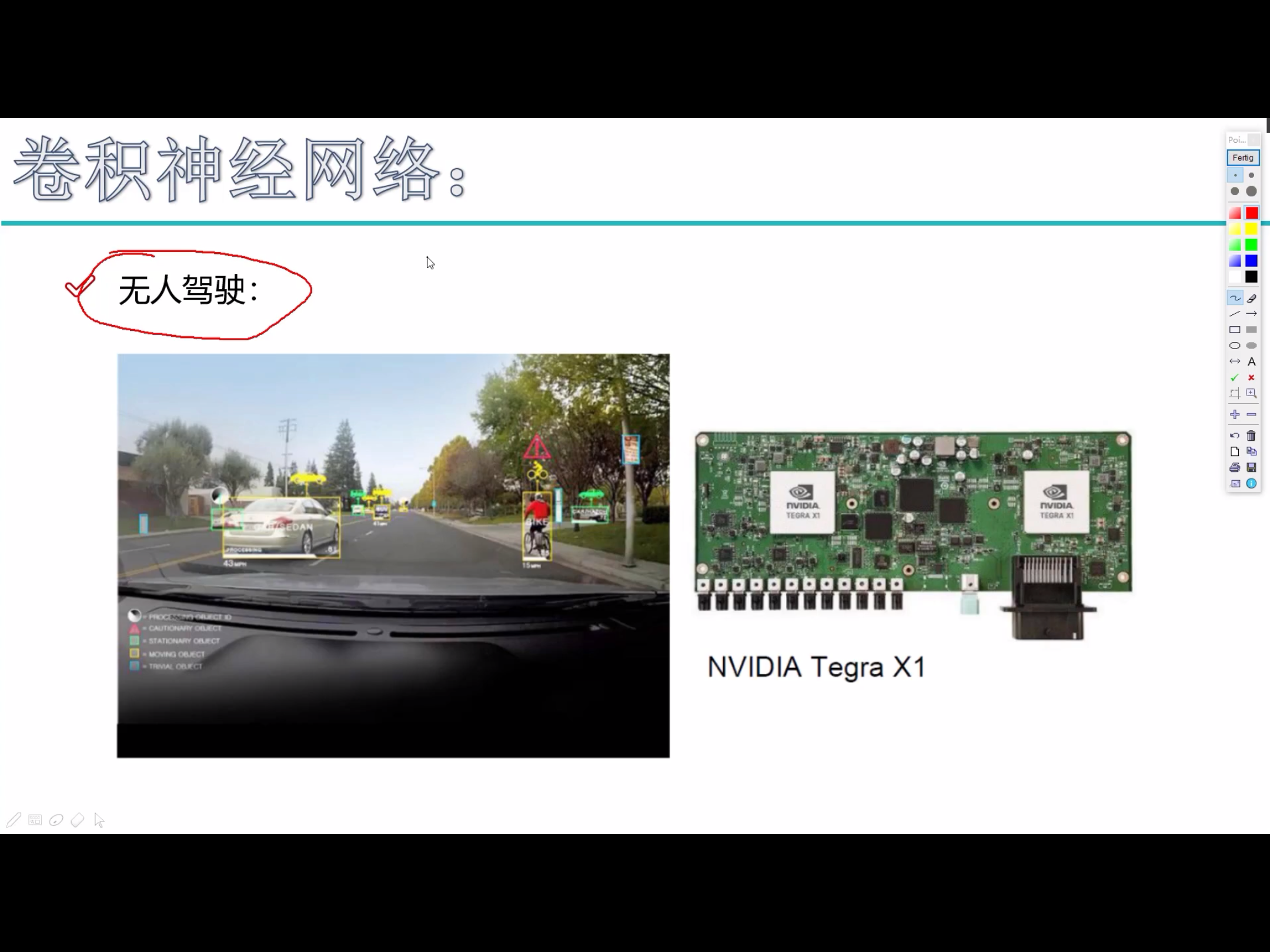
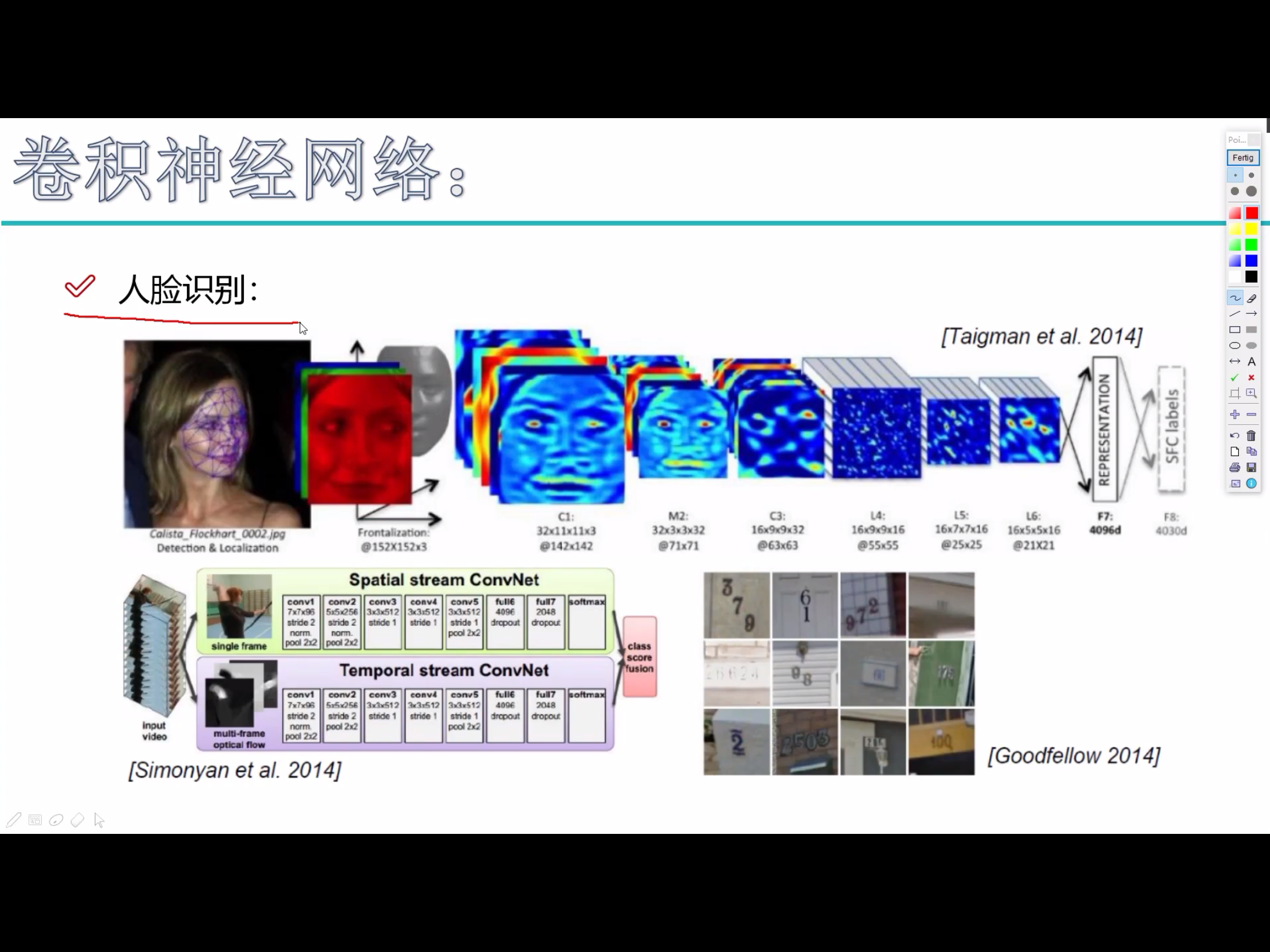
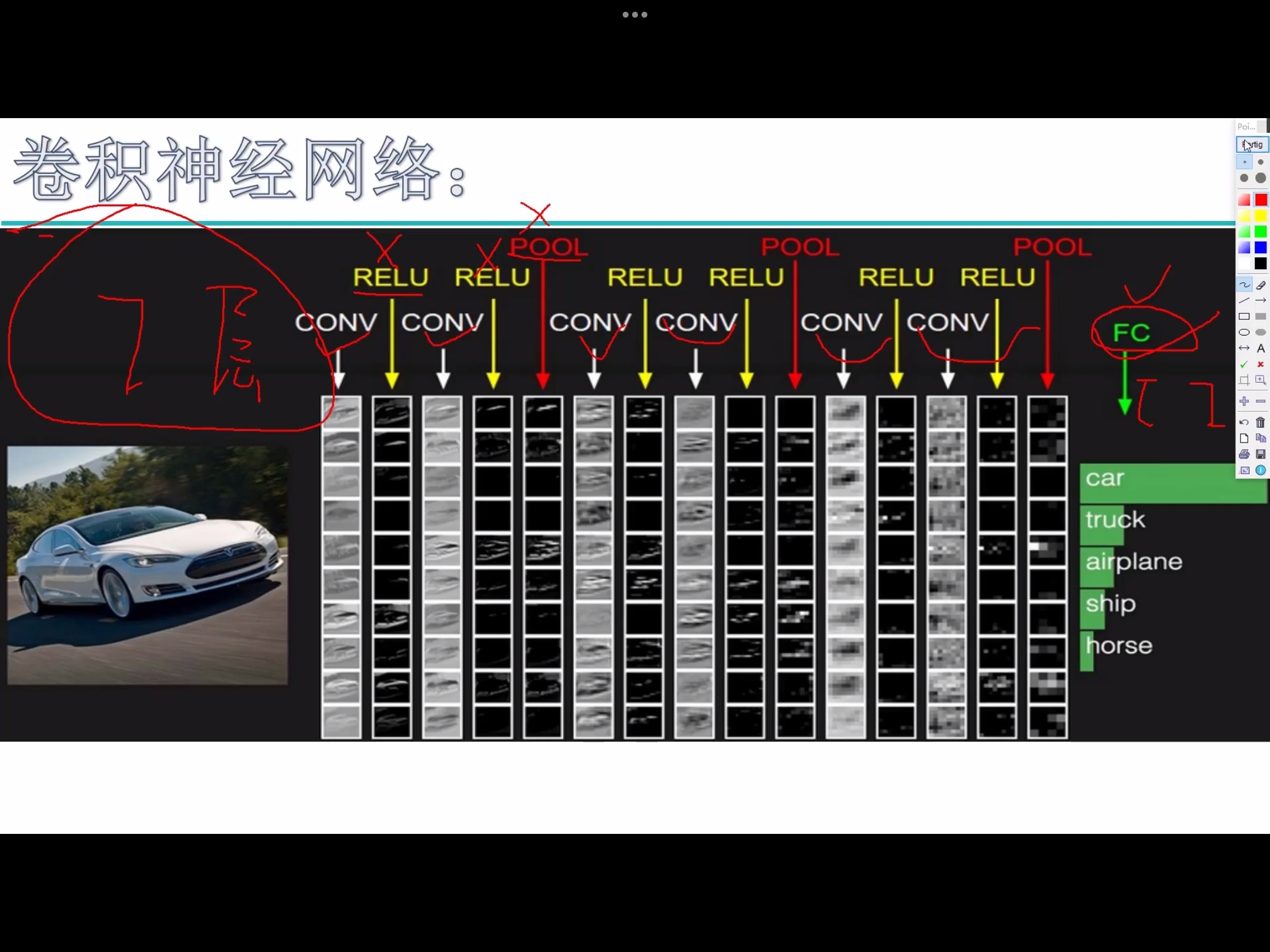
卷积神经网络能干什么


卷积神经网络架构

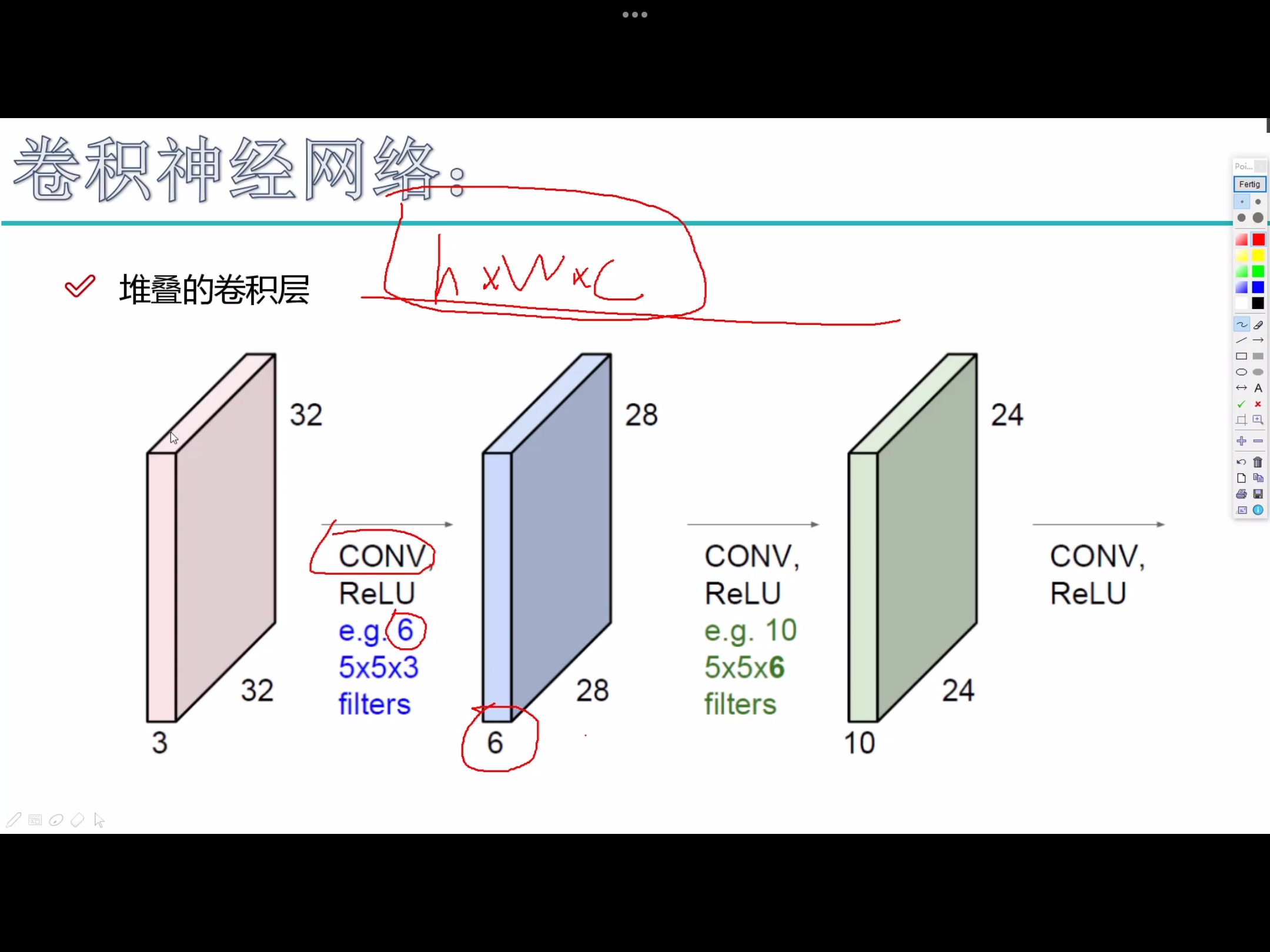
- 红→蓝,
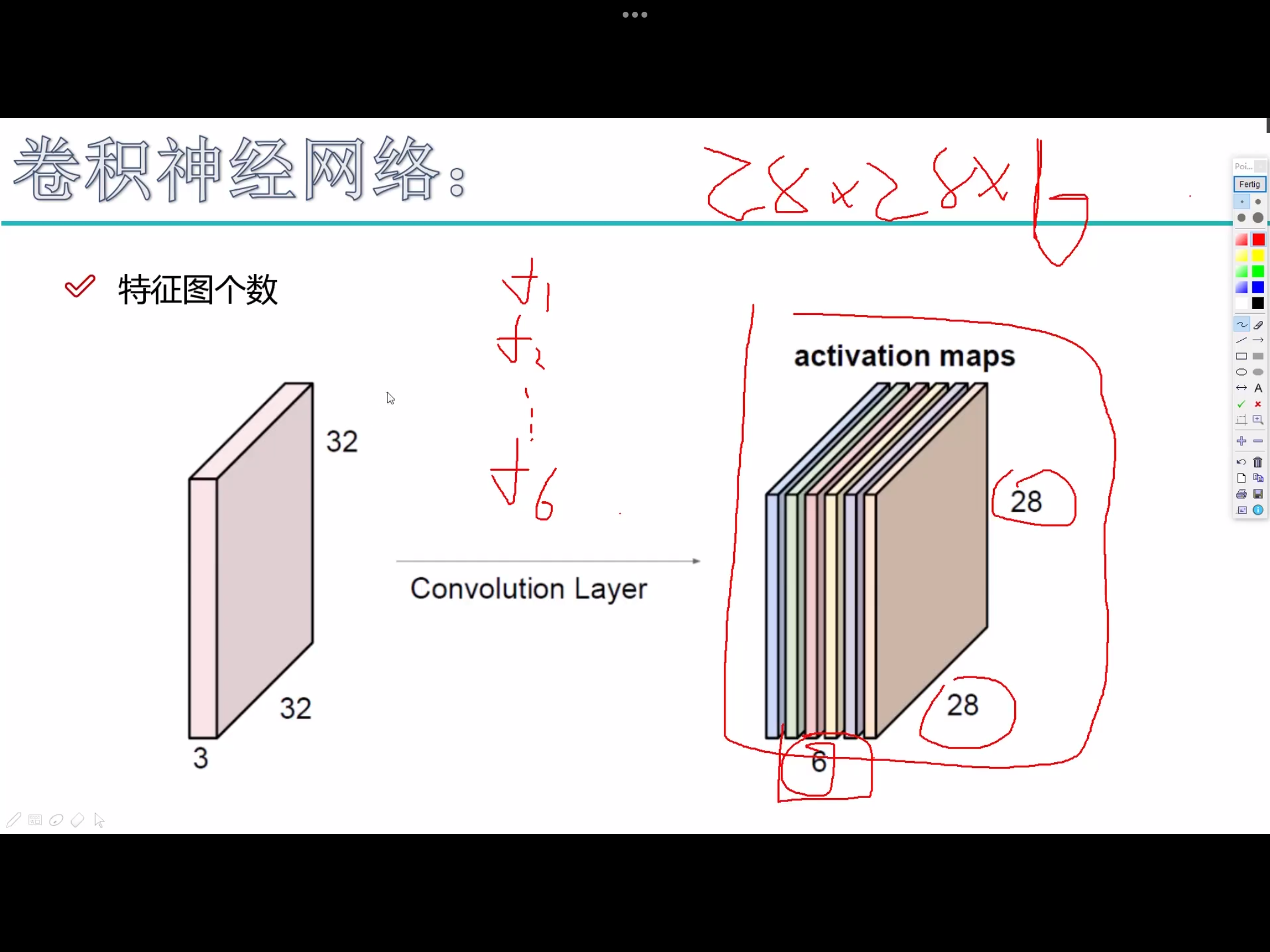
6是代表6个卷积核,每个卷积核是5×5×3,得到的28×28×6 - 蓝→绿,
10是代表10个卷积核,每个卷积核是5×5×6
卷积
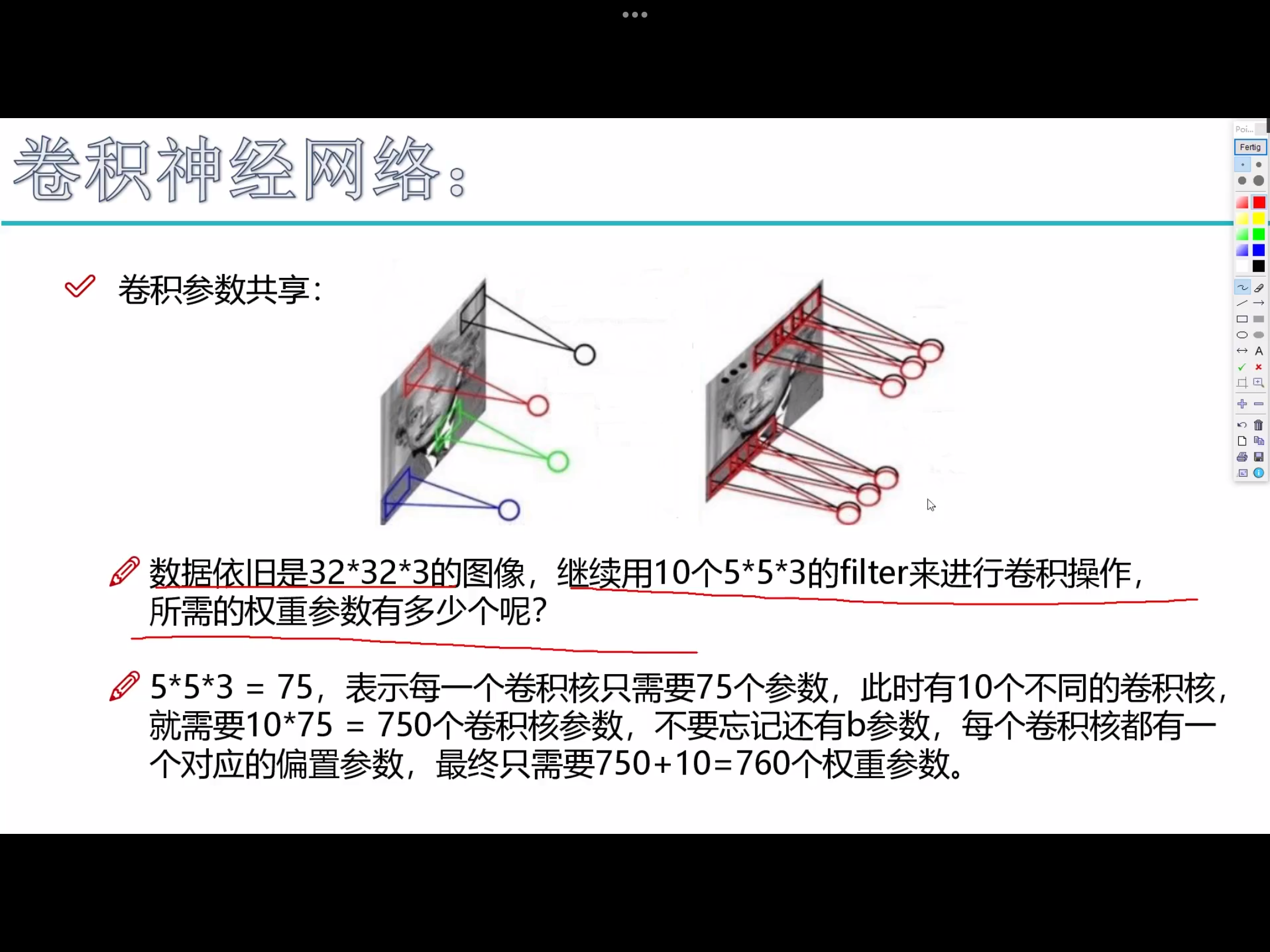
- 卷积核可以拥有多个
- 每个子区域使用相同的卷积核 (卷积参数共享)
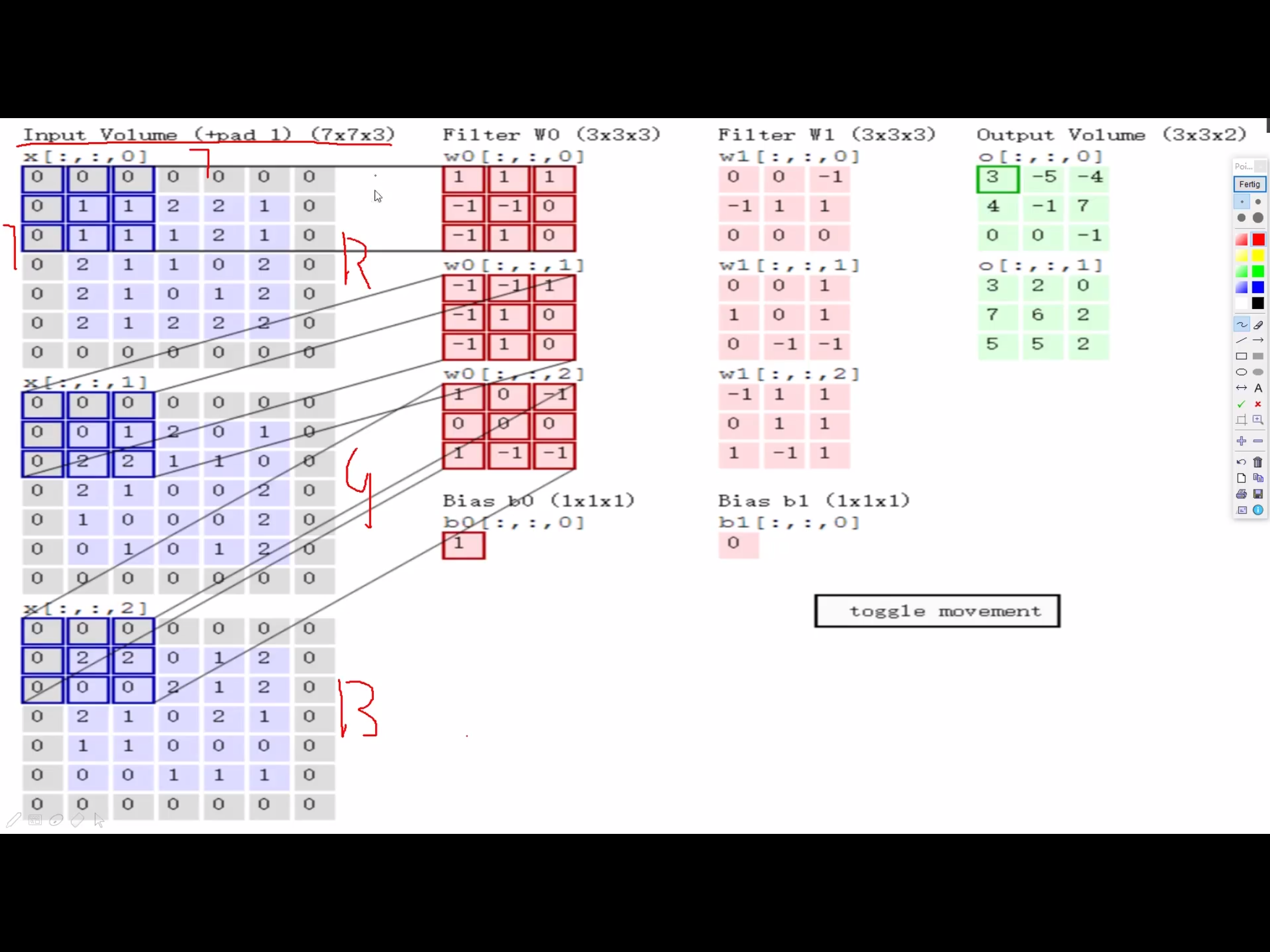
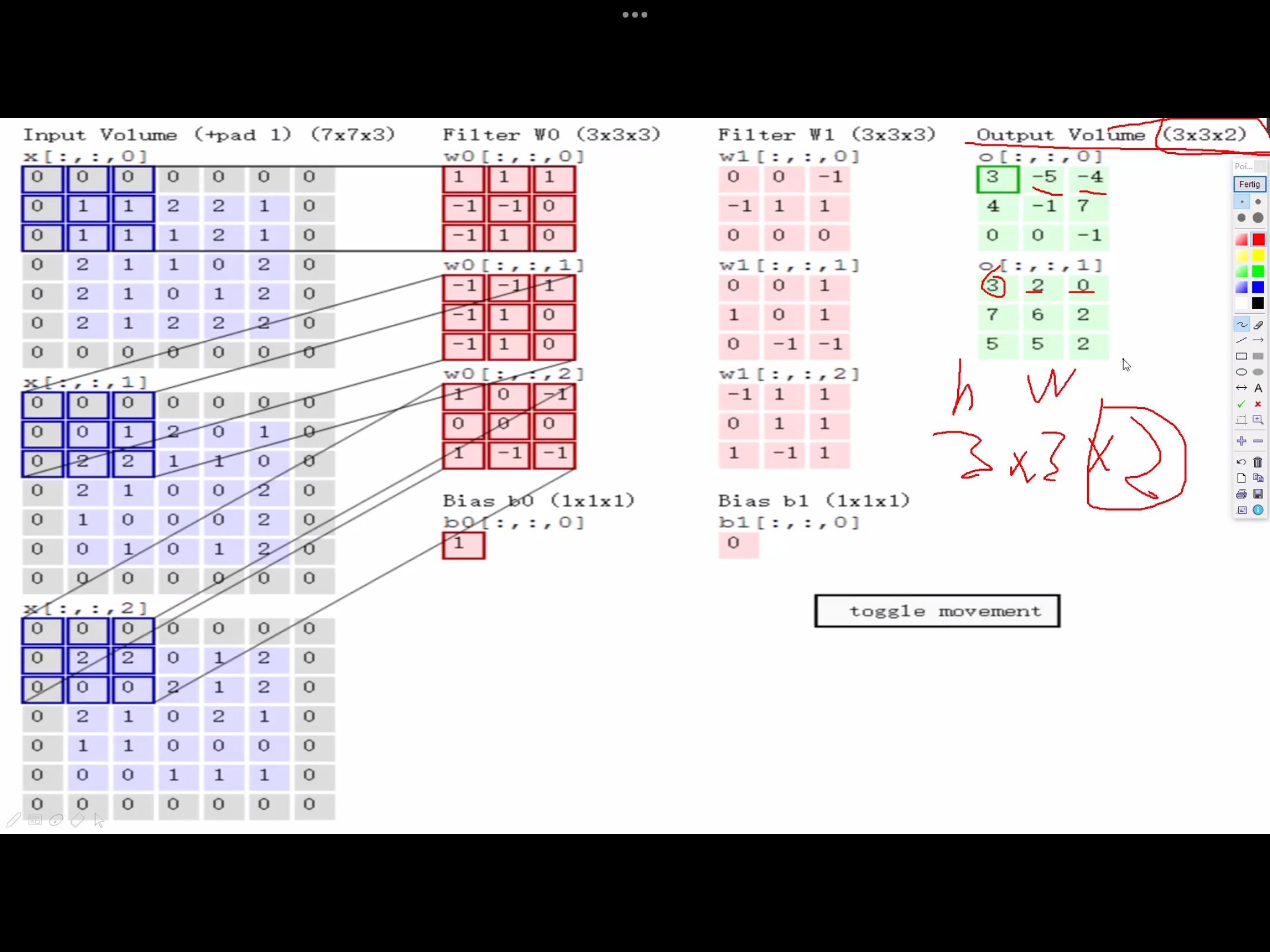
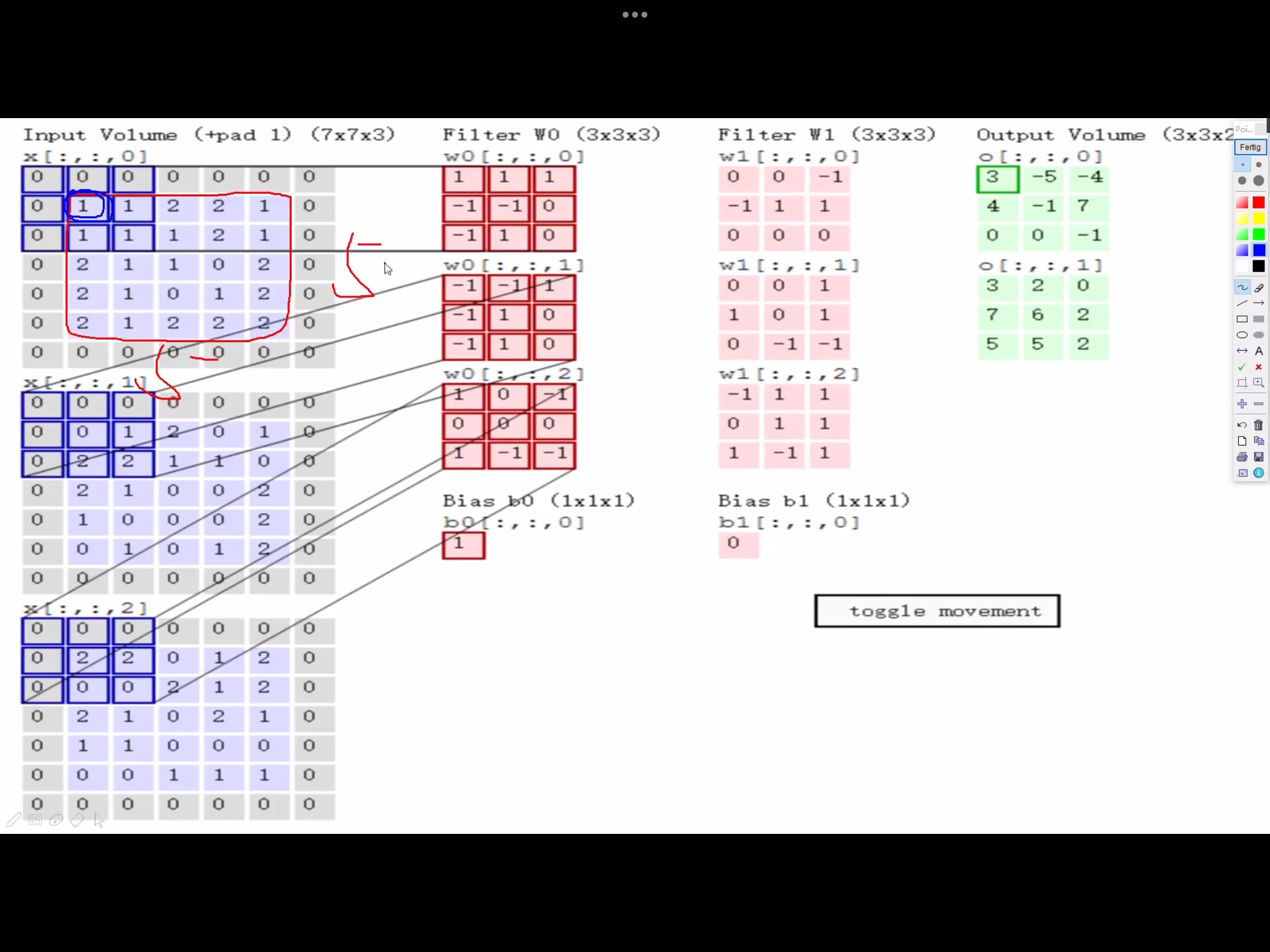
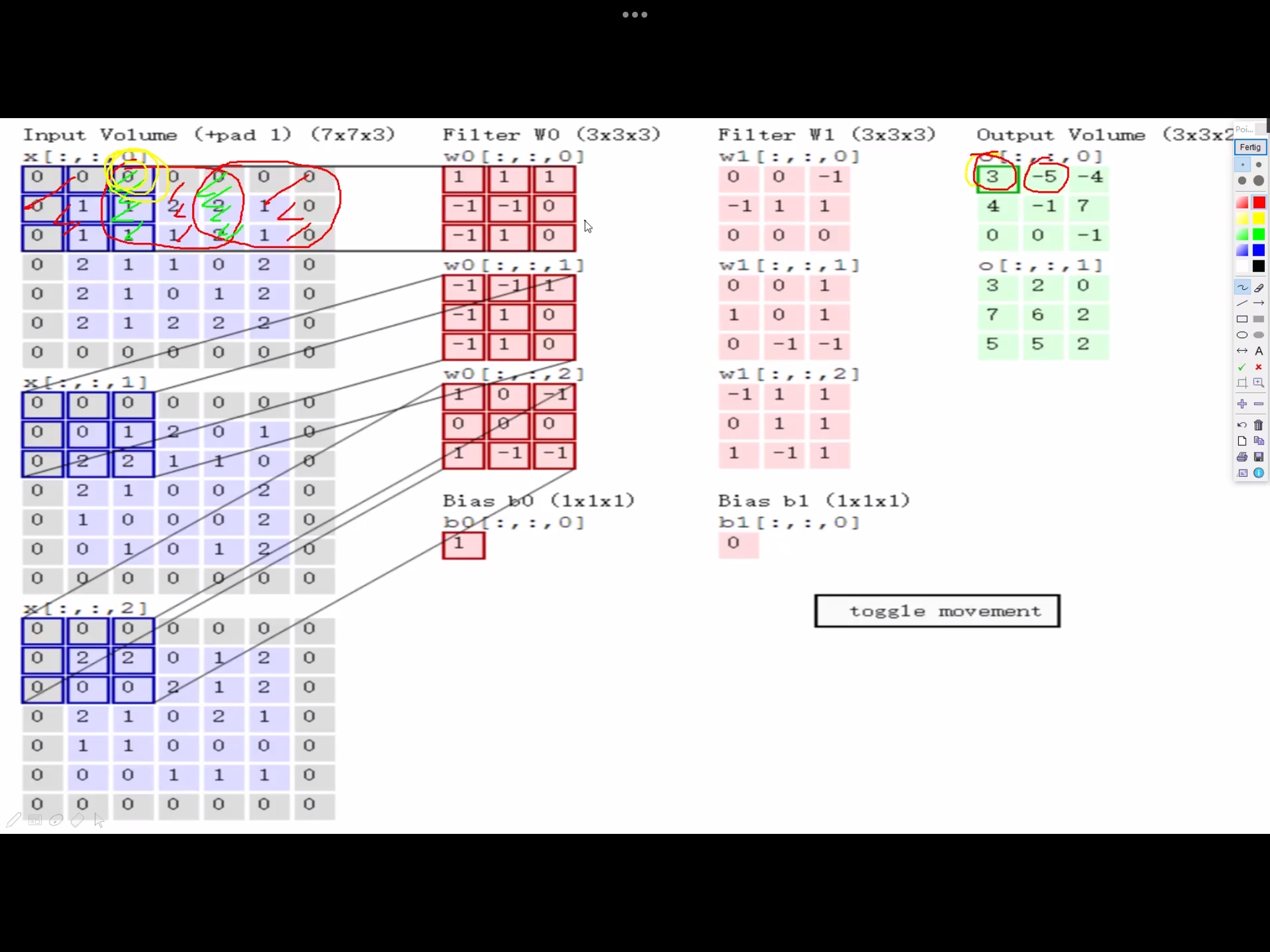
卷积层参数
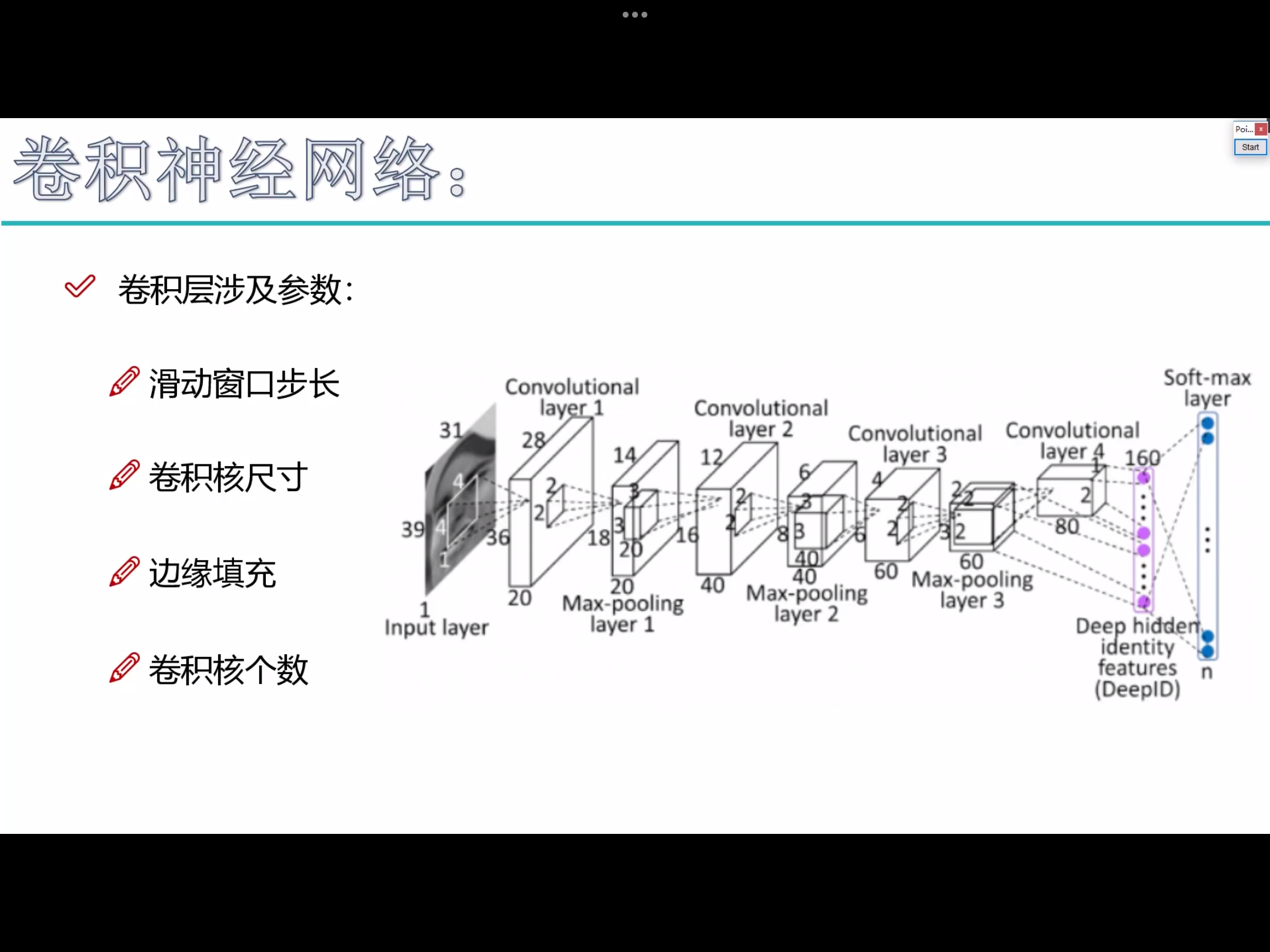
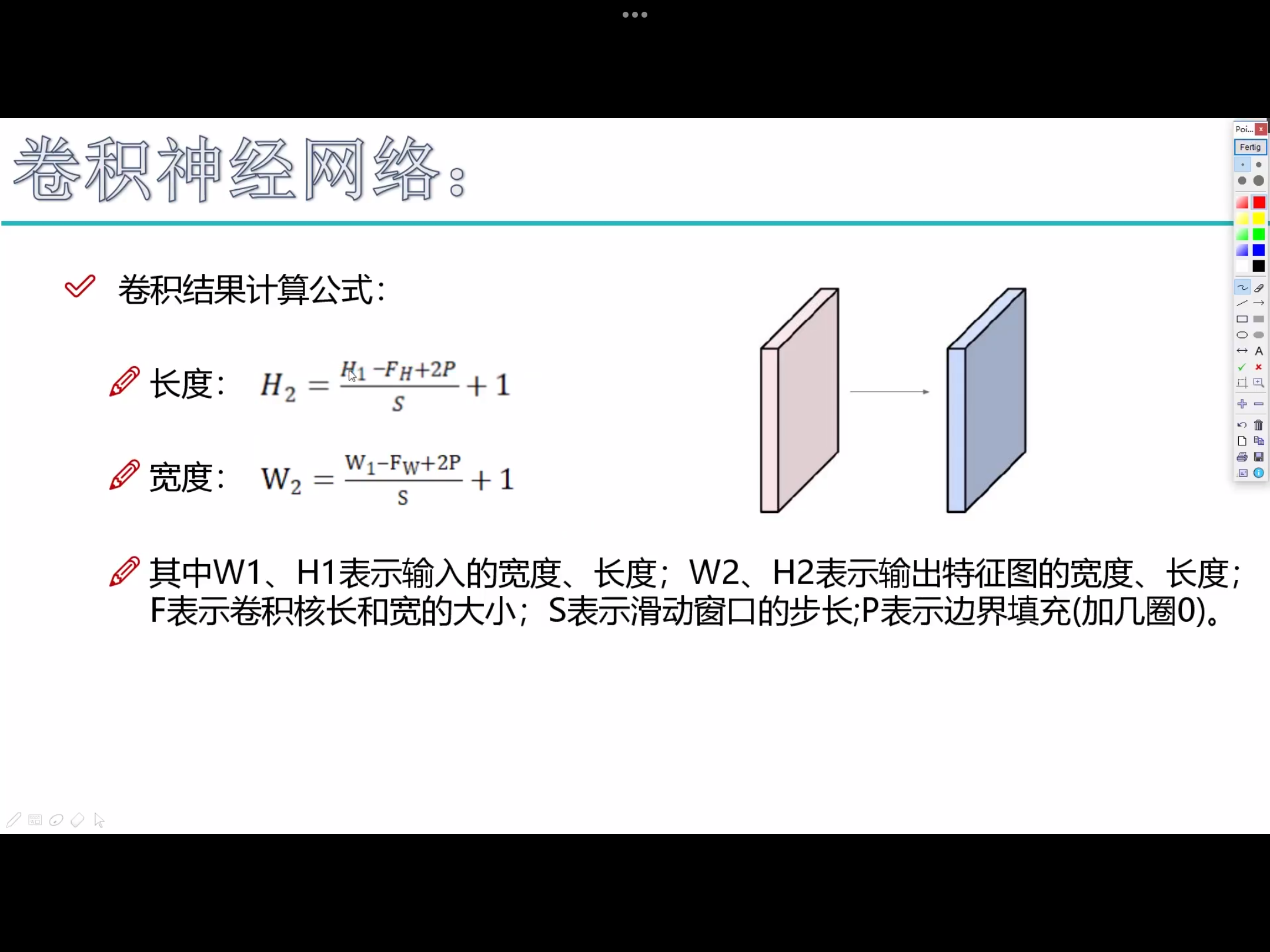
1. 滑动窗口步长 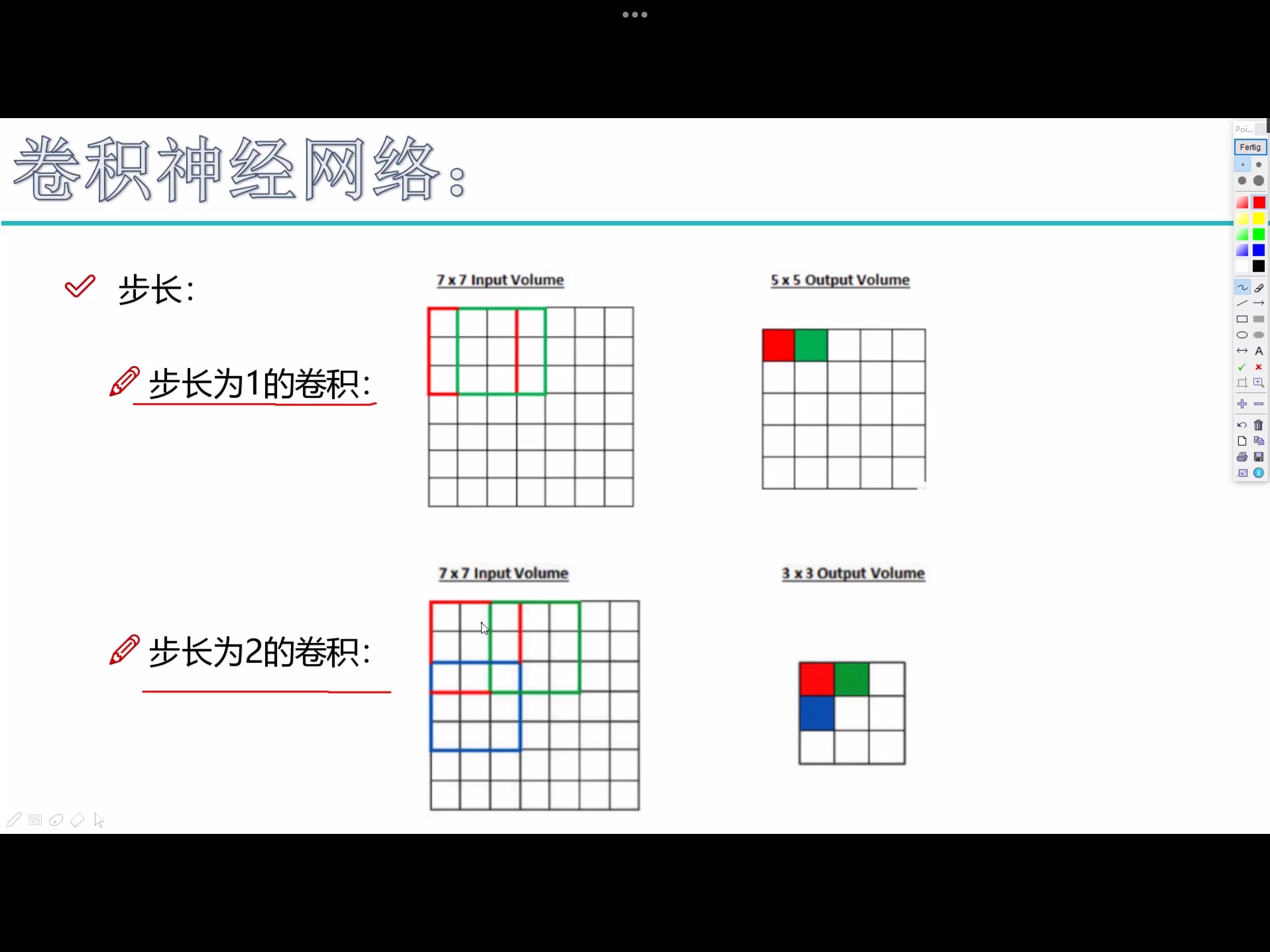
2. 卷积核尺寸 - 一般3*3,尺寸越大,特征提取越粗糙,尺寸越小,特征提取越细腻。
3. 边缘填充 padding
- 越往边界的点,能被利用的次数越少;越往中间的点,能被利用的次数越多。
padding一定程度上弥补了边界信息缺失的问题,加上一圈0,能够使得边缘特征充分的被利用。

pooling
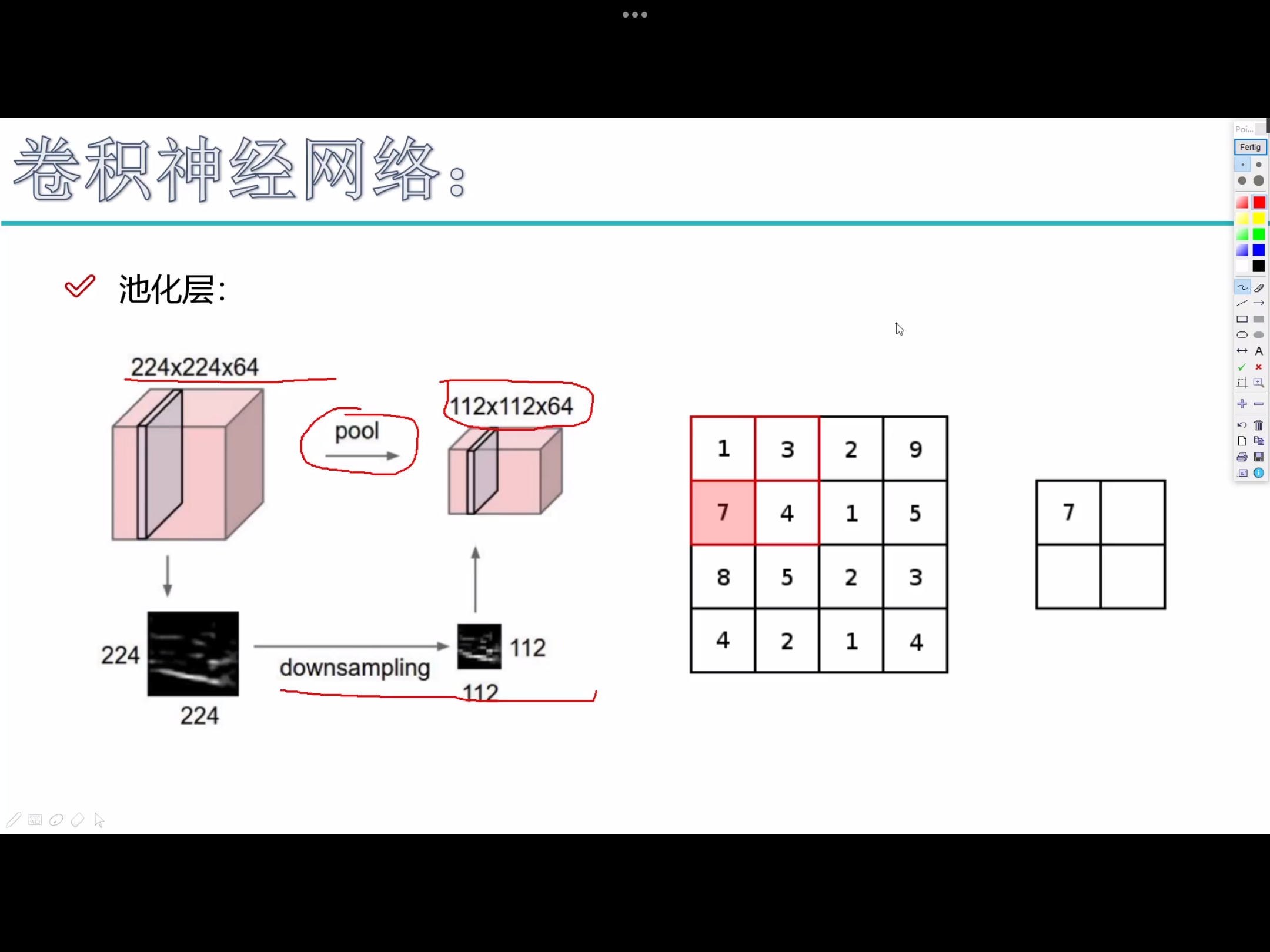
- 特征图个数不会变,只是去变长和宽。
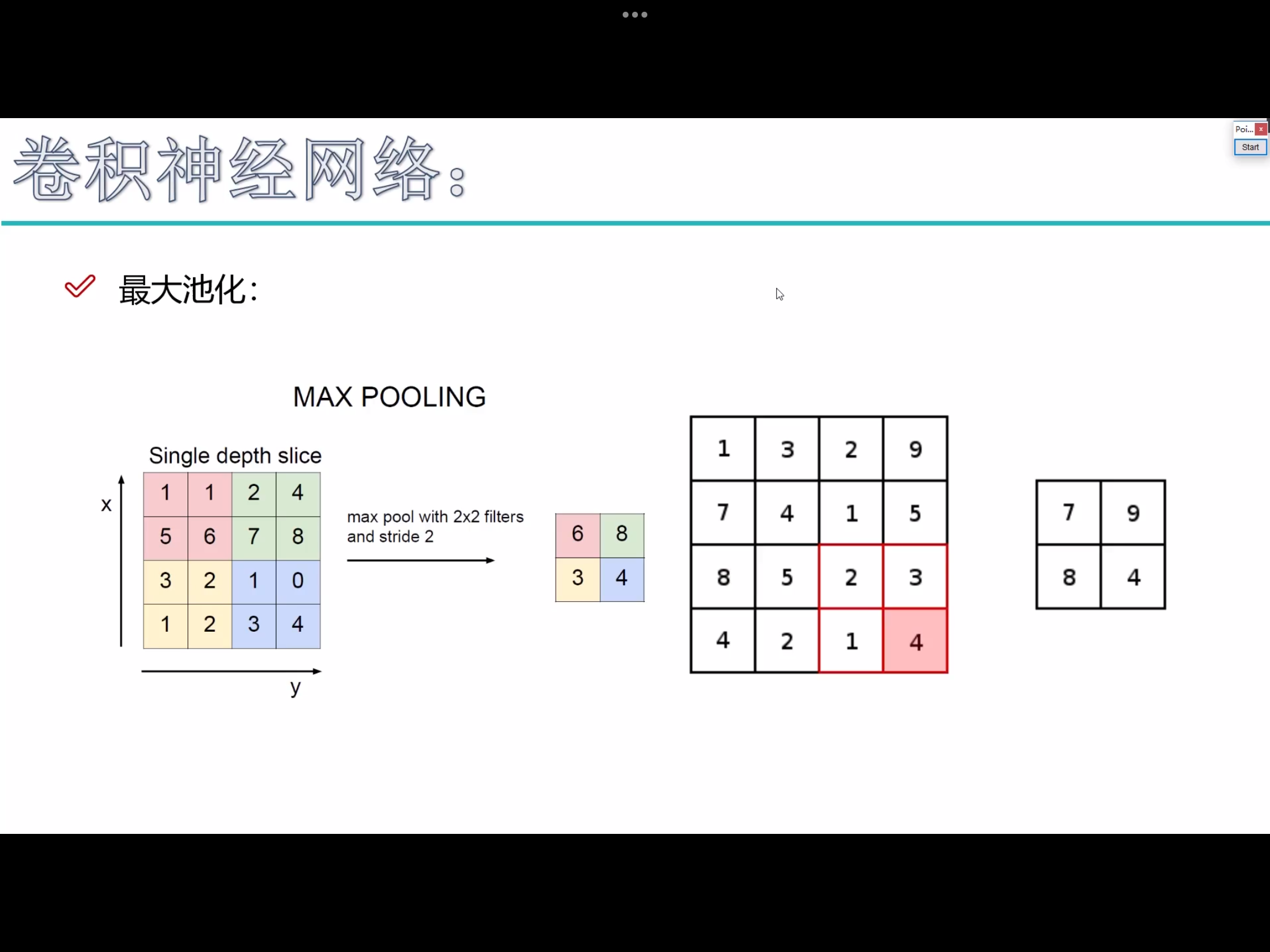
pooling不涉及任何矩阵的计算 - 最大
pooling,在神经网络中,一般认为值越大,特征越明显
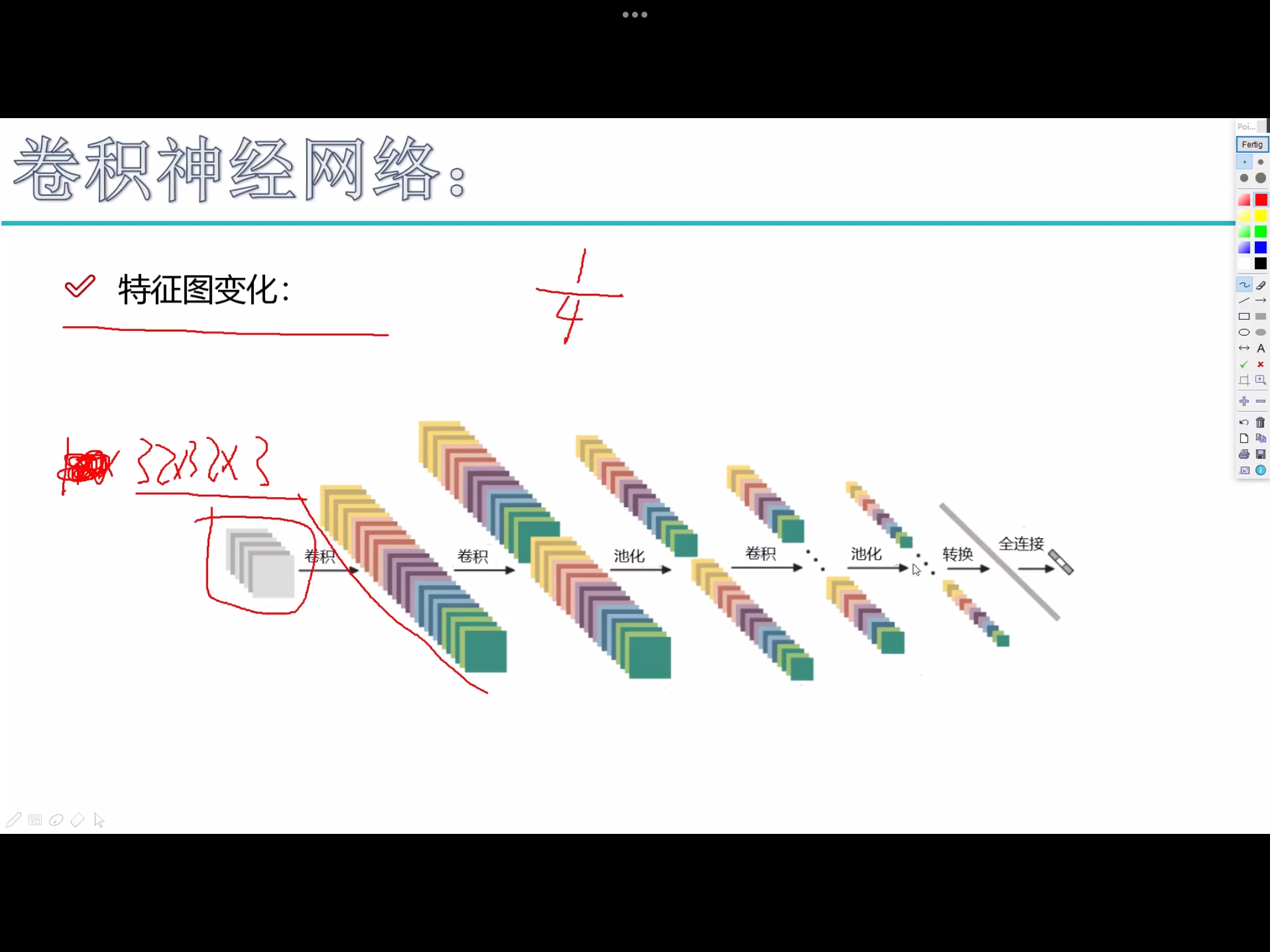
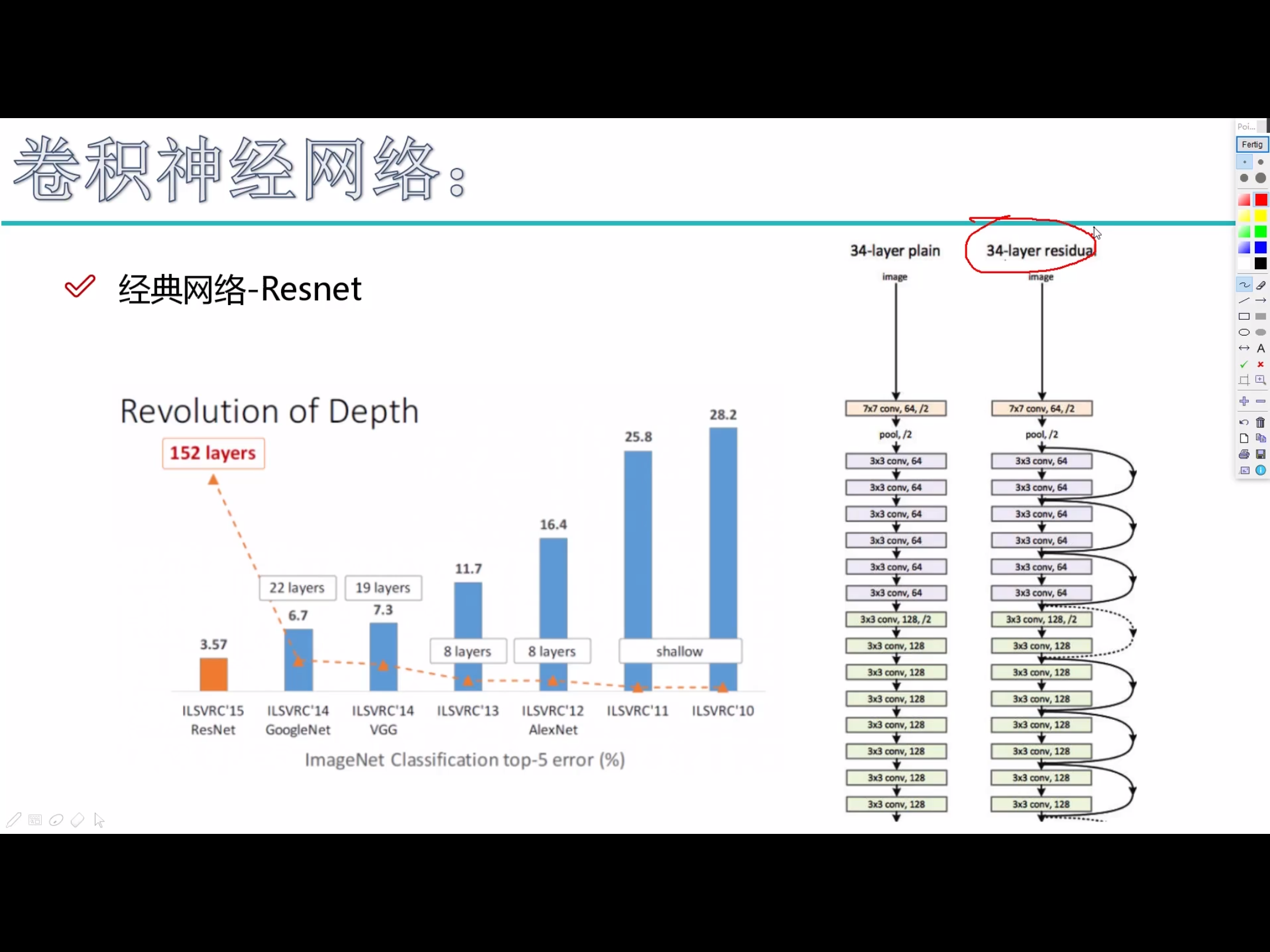
经典卷积神经网络
- 带参数计算 的才能被叫做 层
- 深度学习,用更深的网络结构去提取原始图像中的特征
- 分类还是回归,取决于损失函数和层如何连接
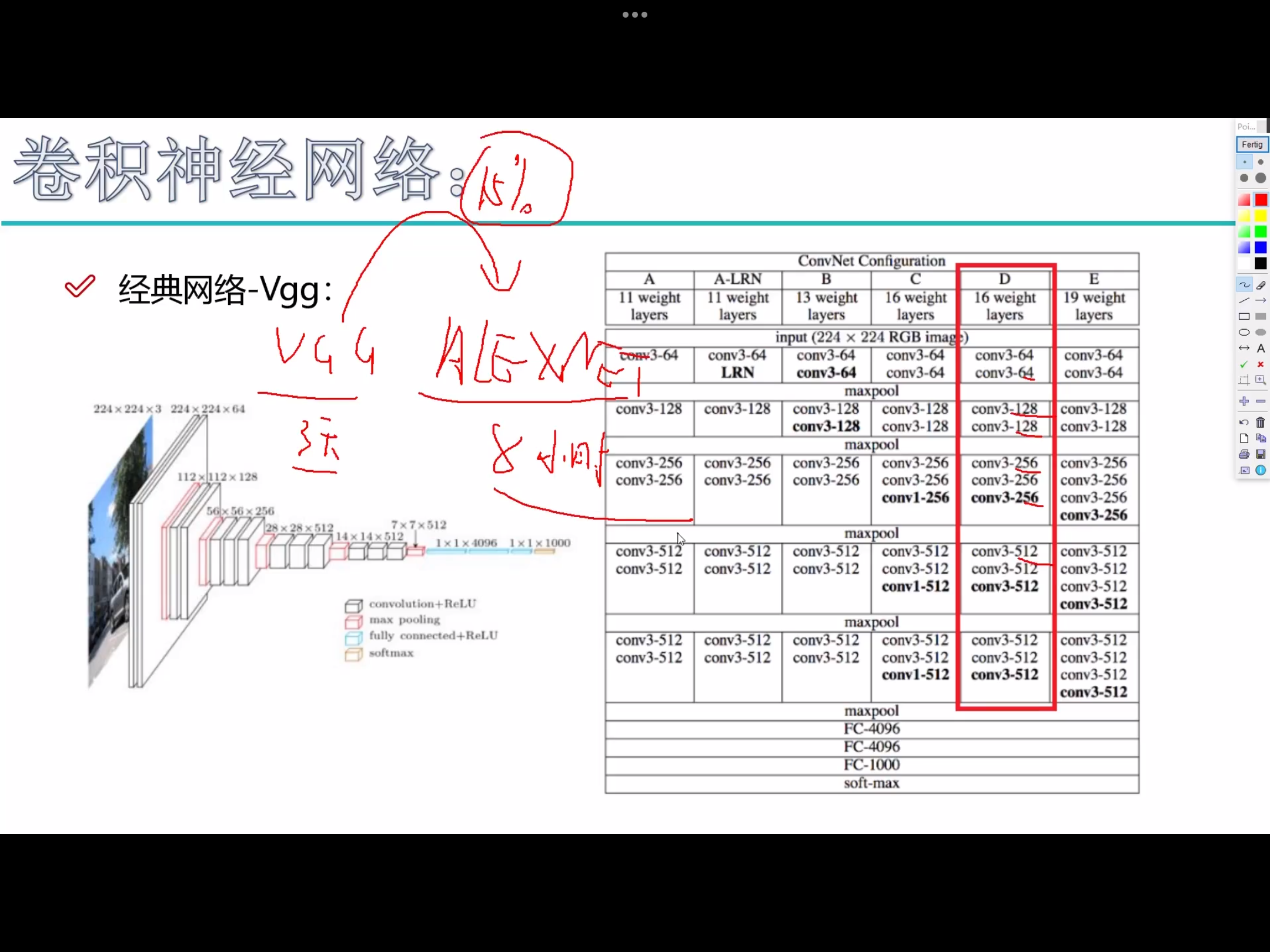
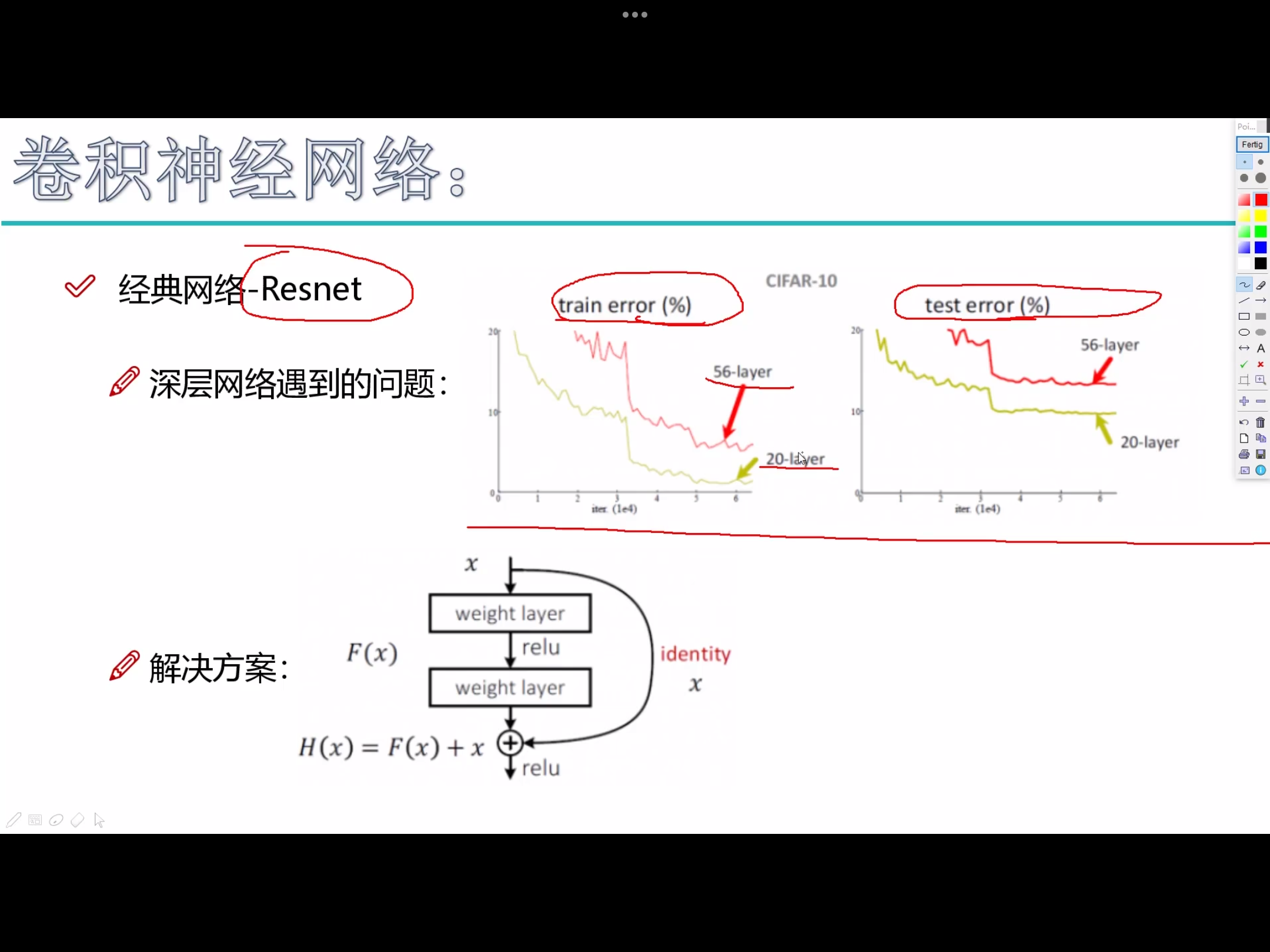
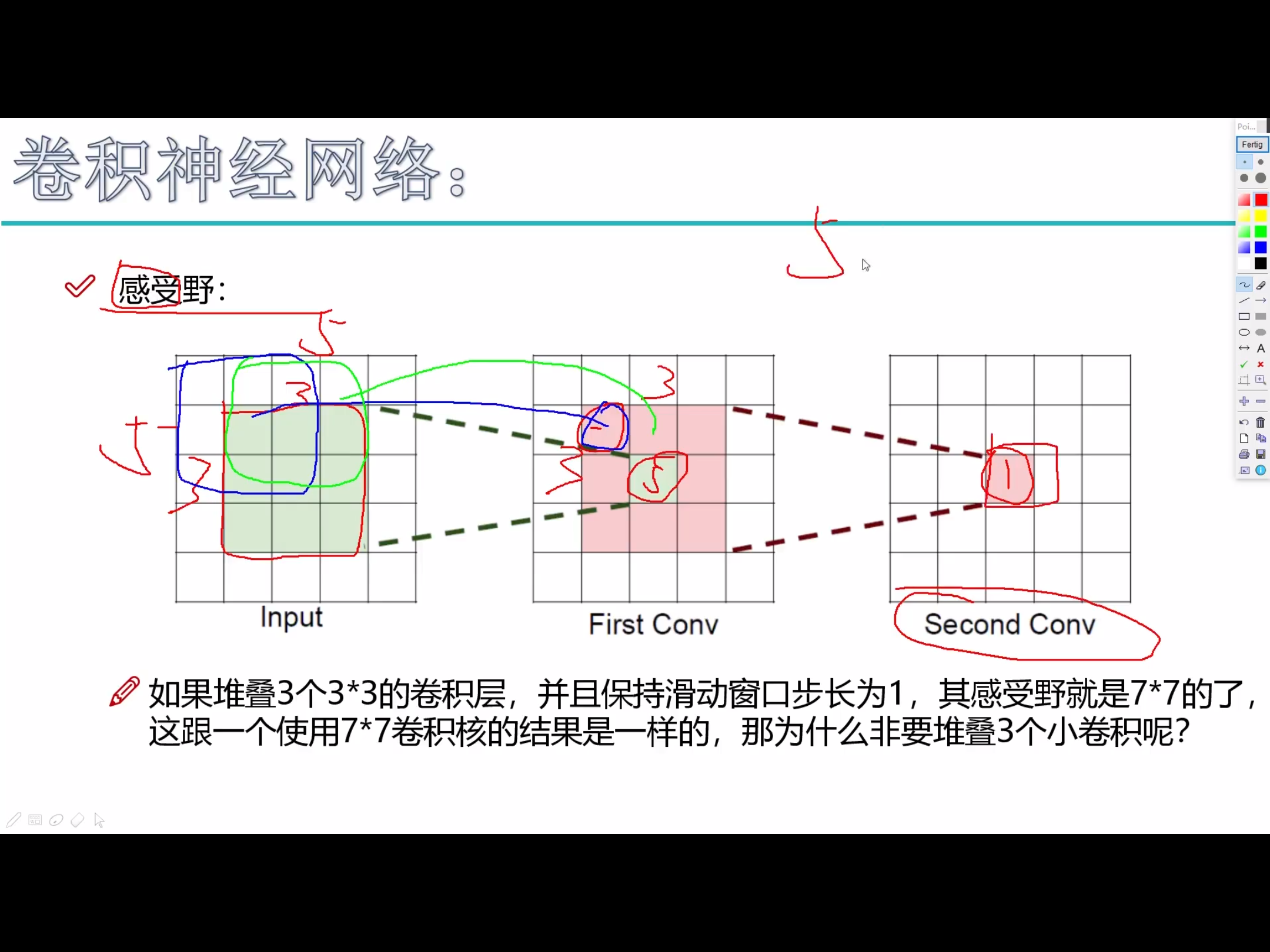
感受野