线性回归
单变量线性回归
梯度下降做的事就是找到一个值 θθ 使得代价函数 J(θ)J(θ) 最小
多变量线性回归
- 通常用 大写、黑体 字母表示矩阵,用小写字母表示标量或向量。
- 正斜体 总的原则是变量(矢量,张量)等用斜体;数字、确定符号、词汇缩缩、单位等用正体。参考 科技论文书写规范之正斜体问题
符号说明
| 符号/变量 | 含义 |
|---|---|
| nn | 特征量的数目 |
| mm | 训练样本的数量 |
| hh | 学习方法的解决方案或函数也称为假设 |
| x(i)x(i) | 第ii个训练样本的输入特征值 |
| x(i)jx(i)j | 第ii个训练样本中第jj个特征量的值 |

 |
|---|
 |
python计算代价函数的代码
1 | def conputeCost (x, y, theta): |
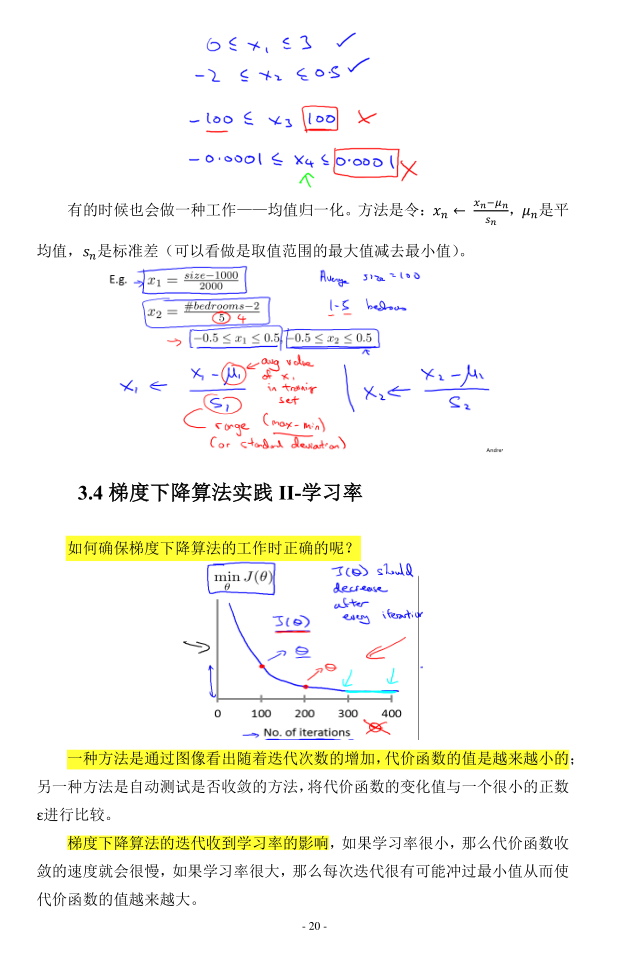
梯度下降 在正常工作。
梯度下降 vs. 正规方程
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要多次迭代 | 一次运算就得出结果 |
| 当特征数量大的时候比较适用 | 计算 (XTX)−1(XTX)−1 如果特征数量很大,则运算的速度就会很慢,矩阵逆运算的时间复杂度是 O(n3)O(n3),通常来说 n<10000 还是可以接受的。 |
| 适用于各种模型 | 只适用与线性模型 |
向量化
使用程序计算这样一个线性回归假设函数:hθ(x)=∑nj=0θjxjhθ(x)=∑nj=0θjxj,可以写成向量的形式: hθ(x)=n∑j=0θjxj=θTxhθ(x)=n∑j=0θjxj=θTx 非向量化实现
1 | double prediction = 0.0; |
向量化实现,使用 C++ 数值线性代数库,更简单、更高效的代码
1 | double prediction = theta.transpose( ) * x; |